Prediction with CNN using 2D lat/lon data#
Author: Eli Holmes (NOAA), Yifei Hang (UW Varanasi intern 2024), Jiarui Yu (UW Varanasi intern 2023)
This notebook shows how to train a basic Convolutional Neural Network on 2D data (a lat/lon grid of environmental variables) to predict a different 2D data layer. Although you can run this tutorial on CPU, it will be much faster on GPU. We used the image quay.io/pangeo/ml-notebook:2025.05.22 for running the notebook.
This will be a toy example of predicting chlorophyll-a using SST and salinity. This won’t work very well but we will learn the process.
Load the libraries that we need#
TensorFlow is a popular open-source Python library for building and training machine learning models, especially deep learning models like neural networks, including convolutional neural networks.
Keras is a high-level interface that runs on top of TensorFlow. It makes it easier to build models by providing simple building blocks like layers, optimizers, and training loops.
In this notebook, we’ll use Keras to:
Build our Convolutional Neural Network (CNN)
Train it to predict ocean chlorophyll from two predictors: SST and salinity
Monitor training performance and make predictions
We use the Keras Conv2D module since we are training on lat/lon 2D spatial data.
# Uncomment this line and run if you are in Colab; leave in the !. That is part of the cmd
# !pip install zarr gcsfs --quiet
# --- Core data handling libraries ---
import xarray as xr # for working with labeled multi-dimensional arrays
import numpy as np # for numerical operations on arrays
import dask.array as da # for lazy, parallel array operations (used in xarray backends)
# --- Plotting ---
import matplotlib.pyplot as plt # for creating plots
# --- TensorFlow setup ---
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # suppress TensorFlow log spam (0=all, 3=only errors)
import tensorflow as tf # main deep learning framework
# --- Keras (part of TensorFlow): building and training neural networks ---
from keras.models import Sequential # lets us stack layers in a simple linear model
from keras.layers import Conv2D # 2D convolution layer — finds spatial patterns in image-like data
from keras.layers import BatchNormalization # stabilizes and speeds up training by normalizing activations
from keras.layers import Dropout # randomly "drops" neurons during training to reduce overfitting
from keras.callbacks import EarlyStopping # stops training early if validation loss doesn't improve
2025-06-09 19:03:24.387990: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2025-06-09 19:03:24.405540: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2025-06-09 19:03:24.410902: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
See what machine we are on#
# list all the physical devices
physical_devices = tf.config.list_physical_devices()
print("All Physical Devices:", physical_devices)
# list all the available GPUs
gpus = tf.config.list_physical_devices('GPU')
print("Available GPUs:", gpus)
# Print infomation for available GPU if there exists any
if gpus:
for gpu in gpus:
details = tf.config.experimental.get_device_details(gpu)
print("GPU Details:", details)
else:
print("No GPU available")
All Physical Devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Available GPUs: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
GPU Details: {'compute_capability': (7, 5), 'device_name': 'Tesla T4'}
Load data#
I created the data for Part I in Data_Prep_Part_1. Here I will load.
# read in the Zarr file; a 3D (time, lat, lon) cube for a bunch of variables in the Indian Ocean
dataset = xr.open_zarr("~/shared/cnn/part1.zarr")
dataset
<xarray.Dataset> Size: 104MB
Dimensions: (lat: 149, lon: 181, time: 321)
Coordinates:
* lat (lat) float32 596B 32.0 31.75 31.5 31.25 ... -4.5 -4.75 -5.0
* lon (lon) float32 724B 45.0 45.25 45.5 45.75 ... 89.5 89.75 90.0
* time (time) datetime64[ns] 3kB 2020-01-01 2020-01-02 ... 2020-12-31
Data variables:
ocean_mask (lat, lon) bool 27kB dask.array<chunksize=(50, 60), meta=np.ndarray>
so (time, lat, lon) float32 35MB dask.array<chunksize=(100, 50, 60), meta=np.ndarray>
sst (time, lat, lon) float32 35MB dask.array<chunksize=(100, 50, 60), meta=np.ndarray>
y (time, lat, lon) float32 35MB dask.array<chunksize=(100, 50, 60), meta=np.ndarray>
Attributes: (12/92)
Conventions: CF-1.8, ACDD-1.3
DPM_reference: GC-UD-ACRI-PUG
IODD_reference: GC-UD-ACRI-PUG
acknowledgement: The Licensees will ensure that original ...
citation: The Licensees will ensure that original ...
cmems_product_id: OCEANCOLOUR_GLO_BGC_L3_MY_009_103
... ...
time_coverage_end: 2024-04-18T02:58:23Z
time_coverage_resolution: P1D
time_coverage_start: 2024-04-16T21:12:05Z
title: cmems_obs-oc_glo_bgc-plankton_my_l3-mult...
westernmost_longitude: -180.0
westernmost_valid_longitude: -180.0Process the data#
We need to split into our training and testing data. I will create some functions to help with this.
Note on Missing Values and Masking (Part 1)
TensorFlow cannot handle any NaNs. In this first part of the tutorial, we are not using a land or CHL mask. Instead, we keep it simple by:
Replacing all missing values (NaNs) with 0
Using the raw
CHLdata as-is, only filtering out days with too many NaNs beforehandTraining the model to learn from the data wherever it exists. It is going to spend extra time learning “CHL” on land where CHL, SST and salinity are all set to 0.
In Part 2, we will show how to handle missing data more carefully using a mask during training.
import numpy as np
import dask.array as da
def time_series_split(data, pred_var, split_ratio=(0.7, 0.2, 0.1)):
"""
Splits data into train, validation, and test sets.
Replaces all NaNs with 0s and is robust to variable dimension order.
Parameters:
data: xarray dataset containing predictors and a "y" response
pred_var: list of predictor variable names
split_ratio: tuple of 3 floats summing to 1.0 (train, val, test)
Returns:
X (full input), y (full label),
and tuple of splits: X_train, y_train, X_val, y_val, X_test, y_test
"""
# Ensure consistent order: bring time to the first axis
time_dim = 'time'
if time_dim not in data.dims:
raise ValueError("Dataset must contain a 'time' dimension.")
# Stack and fill NaNs for predictors
pred_arrays = []
for var in pred_var:
arr = data[var].transpose(time_dim, ...) # time first
arr = da.nan_to_num(arr.data)
pred_arrays.append(arr)
X = da.stack(pred_arrays, axis=-1) # (time, lat, lon, n_features)
# Process label
y = data["y"].transpose(time_dim, ...).data # (time, lat, lon)
y = da.nan_to_num(y)
# Split based on time dimension
total_length = X.shape[0]
train_end = int(total_length * split_ratio[0])
val_end = int(total_length * (split_ratio[0] + split_ratio[1]))
X_train = X[:train_end]
y_train = y[:train_end]
X_val = X[train_end:val_end]
y_val = y[train_end:val_end]
X_test = X[val_end:]
y_test = y[val_end:]
return X, y, X_train, y_train, X_val, y_val, X_test, y_test
Here we create our training and test data with 2 variables using only 2020. 70% data for training, 20% for validation and 10% for testing.
pred_var = ['sst', 'so']
split_ratio = [.7, .2, .1]
X, y, X_train, y_train, X_val, y_val, X_test, y_test = time_series_split(dataset, pred_var, split_ratio)
Create the CNN model#
from keras.models import Sequential
from keras.layers import Input, Conv2D, BatchNormalization, Dropout
def create_model_CNN(input_shape):
"""
Create a simple 3-layer CNN model for gridded ocean data.
Parameters
----------
input_shape : tuple
The shape of each sample, e.g., (149, 181, 2)
Returns
-------
model : keras.Model
CNN model to predict CHL from SST and salinity
"""
model = Sequential()
# Input layer defines the input dimensions for the CNN
model.add(Input(shape=input_shape))
# Layer 1 — learns fine-scale 3x3 spatial features
# Let the model learn 64 different patterns (filters) in the data at this layer.
# activation relu is non-linearity
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
# Layer 2 — expands context to 5x5; combines fine features into larger structures
# Reduce the number of patterns (filters) so we gradually reduce model complexity
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
# Layer 3 — has access to ~7x7 neighborhood; outputs CHL prediction per pixel
# Combines all the previous layer’s features into a CHL estimate at each pixel
# 1 response (chl) — hence, 1 prediction pixel = filter
# linear since predicting a real continuous variable (log CHL)
model.add(Conv2D(filters=1, kernel_size=(3, 3), padding='same', activation='linear'))
return model
Let’s build the model#
We build a simple 3-layer CNN model. Each layer preserves the (lat, lon) shape and learns filters to extract spatial patterns. The model has ~20,000 trainable parameters, which we can see from model.summary(). This is small compared to huge modern CNNs (millions of parameters).
# Get shape of one input sample: (lat, lon, n_features)
input_shape = X_train.shape[1:]
# Create the model using the correct input shape
model = create_model_CNN(input_shape)
# Check the model summary
# model.summary()
Let’s train the model#
# Compile the model with Adam optimizer and mean absolute error (MAE) as both loss and evaluation metric
model.compile(
optimizer='adam', # Efficient and widely used optimizer
loss='mae', # Mean Absolute Error: good for continuous data like CHL
metrics=['mae'] # Also track MAE during training/validation
)
# Set up early stopping to prevent overfitting
early_stop = EarlyStopping(
patience=10, # Stop if validation loss doesn't improve for 10 epochs
restore_best_weights=True # Revert to the model weights from the best epoch
)
# Create a TensorFlow dataset for training
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024) # Shuffle the data (helps generalization)
train_dataset = train_dataset.batch(8) # Batch size = 8
# Create a TensorFlow dataset for validation (no shuffle)
val_dataset = tf.data.Dataset.from_tensor_slices((X_val, y_val))
val_dataset = val_dataset.batch(8)
# Train the model
history = model.fit(
train_dataset,
epochs=50, # Maximum number of training epochs
validation_data=val_dataset, # Use validation data during training
callbacks=[early_stop] # Stop early if no improvement
)
Epoch 1/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 7s 43ms/step - loss: 1.2565 - mae: 1.2565 - val_loss: 1.7781 - val_mae: 1.7781
Epoch 2/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.8901 - mae: 0.8901 - val_loss: 0.5457 - val_mae: 0.5457
Epoch 3/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.5741 - mae: 0.5741 - val_loss: 0.9342 - val_mae: 0.9342
Epoch 4/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.4742 - mae: 0.4742 - val_loss: 0.3973 - val_mae: 0.3973
Epoch 5/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.4337 - mae: 0.4337 - val_loss: 0.5859 - val_mae: 0.5859
Epoch 6/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.4100 - mae: 0.4100 - val_loss: 0.5445 - val_mae: 0.5445
Epoch 7/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3833 - mae: 0.3833 - val_loss: 0.6146 - val_mae: 0.6146
Epoch 8/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3734 - mae: 0.3734 - val_loss: 0.3375 - val_mae: 0.3375
Epoch 9/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3581 - mae: 0.3581 - val_loss: 0.2984 - val_mae: 0.2984
Epoch 10/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3489 - mae: 0.3489 - val_loss: 0.3861 - val_mae: 0.3861
Epoch 11/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3462 - mae: 0.3462 - val_loss: 0.2795 - val_mae: 0.2795
Epoch 12/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.3242 - mae: 0.3242 - val_loss: 0.4062 - val_mae: 0.4062
Epoch 13/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.3331 - mae: 0.3331 - val_loss: 0.3003 - val_mae: 0.3003
Epoch 14/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.3239 - mae: 0.3239 - val_loss: 0.3032 - val_mae: 0.3032
Epoch 15/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3149 - mae: 0.3149 - val_loss: 0.2861 - val_mae: 0.2861
Epoch 16/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.3097 - mae: 0.3097 - val_loss: 0.3265 - val_mae: 0.3265
Epoch 17/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.3136 - mae: 0.3136 - val_loss: 0.3032 - val_mae: 0.3032
Epoch 18/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3037 - mae: 0.3037 - val_loss: 0.2902 - val_mae: 0.2902
Epoch 19/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 0.2981 - mae: 0.2981 - val_loss: 0.2983 - val_mae: 0.2983
Epoch 20/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3054 - mae: 0.3054 - val_loss: 0.3271 - val_mae: 0.3271
Epoch 21/50
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.3065 - mae: 0.3065 - val_loss: 0.3541 - val_mae: 0.3541
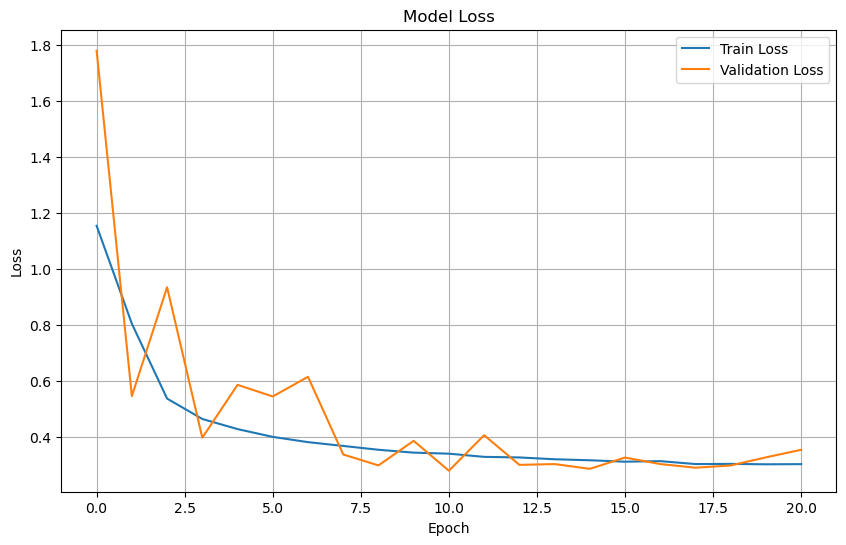
Plot training & validation loss values#
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
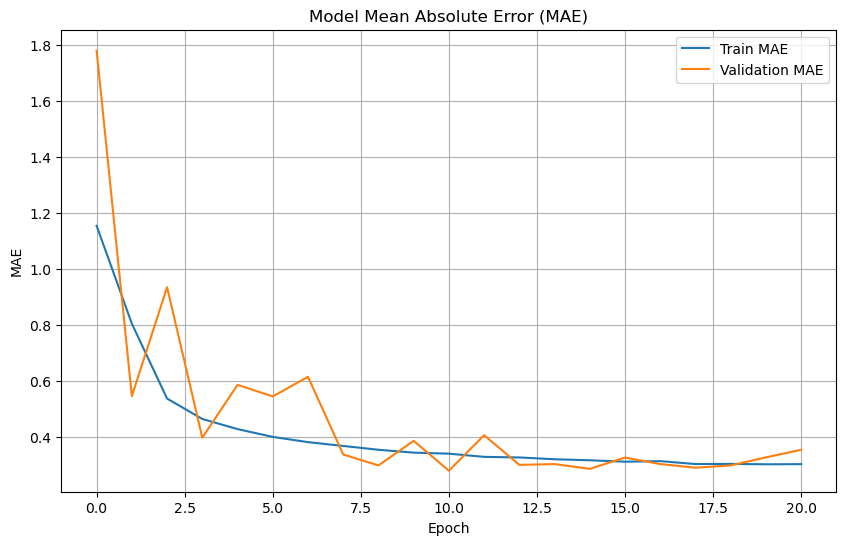
# Plot training & validation MAE values
plt.figure(figsize=(10, 6))
plt.plot(history.history['mae'], label='Train MAE')
plt.plot(history.history['val_mae'], label='Validation MAE')
plt.title('Model Mean Absolute Error (MAE)')
plt.xlabel('Epoch')
plt.ylabel('MAE')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
Prepare test dataset#
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
test_dataset = test_dataset.batch(4)
# Evaluate the model on the test dataset
test_loss, test_mae = model.evaluate(test_dataset)
print(f"Test Loss: {test_loss}")
print(f"Test MAE: {test_mae}")
9/9 ━━━━━━━━━━━━━━━━━━━━ 1s 44ms/step - loss: 0.2382 - mae: 0.2382
Test Loss: 0.23330272734165192
Test MAE: 0.23330272734165192
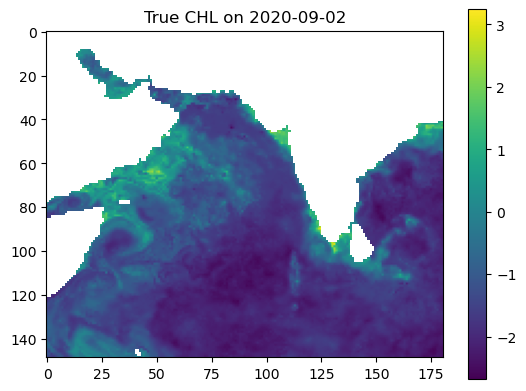
Make some maps of our predictions#
import numpy as np
import matplotlib.pyplot as plt
# Example: date to predict
date_to_predict = np.datetime64("2020-09-02")
# Get index of that date
available_times = dataset["time"].values
date_index = np.where(available_times == date_to_predict)[0][0]
# Prepare input (X: shape = [time, lat, lon, n_features])
input_data = X[date_index] # shape = (lat, lon, n_features)
input_data = np.array(input_data) # convert to numpy
# Predict
predicted_output = model.predict(input_data[np.newaxis, ...])[0]
predicted_output = predicted_output[:, :, 0] # shape = (lat, lon)
# True value from y
true_output = y[date_index]
# Mask land (land_mask = ~ocean)
land_mask = ~dataset["ocean_mask"].values
predicted_output[land_mask] = np.nan
true_output = np.where(land_mask, np.nan, true_output)
# Plot
vmin = np.nanmin([true_output, predicted_output])
vmax = np.nanmax([true_output, predicted_output])
plt.imshow(true_output, vmin=vmin, vmax=vmax)
plt.colorbar()
plt.title(f"True CHL on {date_to_predict}")
plt.show()
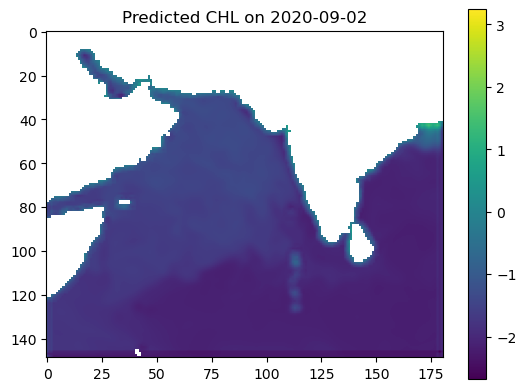
plt.imshow(predicted_output, vmin=vmin, vmax=vmax)
plt.colorbar()
plt.title(f"Predicted CHL on {date_to_predict}")
plt.show()
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
Let’s look at all the months#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import r2_score
# Get available time points and group by month
available_dates = pd.to_datetime(dataset.time.values)
monthly_dates = (
pd.Series(available_dates)
.groupby([available_dates.year, available_dates.month])
.min()
.sort_values()
)[:12] # First 12 months
# lat/lon info
lat = dataset.lat.values
lon = dataset.lon.values
extent = [lon.min(), lon.max(), lat.min(), lat.max()]
flip_lat = lat[0] > lat[-1]
land_mask = ~dataset["ocean_mask"].values
# Create figure and axes
fig, axs = plt.subplots(12, 2, figsize=(7, 24), constrained_layout=True)
for i, date in enumerate(monthly_dates):
# Get time index
date_index = np.where(available_dates == date)[0][0]
# True output
true_output = dataset['y'].sel(time=date).values
if flip_lat:
true_output = np.flipud(true_output)
# Prediction
input_data = np.array(X[date_index])
predicted_output = model.predict(input_data[np.newaxis, ...])[0]
predicted_output = predicted_output[:, :, 0] # shape = (lat, lon)
# Mask land (land_mask = ~ocean)
predicted_output[land_mask] = np.nan
if flip_lat:
predicted_output = np.flipud(predicted_output)
# Shared color scale
vmin = np.nanpercentile([true_output, predicted_output], 5)
vmax = np.nanpercentile([true_output, predicted_output], 95)
# Compute R² (flatten and mask NaNs)
true_flat = true_output.flatten()
pred_flat = predicted_output.flatten()
valid_mask = ~np.isnan(true_flat) & ~np.isnan(pred_flat)
r2 = r2_score(true_flat[valid_mask], pred_flat[valid_mask])
# Plot true
axs[i, 0].imshow(true_output, origin='lower', extent=extent,
vmin=vmin, vmax=vmax, cmap='viridis', aspect='auto')
axs[i, 0].set_title(f"{date.strftime('%b')} — True", fontsize=10)
axs[i, 0].axis('off')
# Plot predicted with R²
axs[i, 1].imshow(predicted_output, origin='lower', extent=extent,
vmin=vmin, vmax=vmax, cmap='viridis', aspect='auto')
axs[i, 1].set_title(f"{date.strftime('%b')} — Pred\n$R^2$ = {r2:.2f}", fontsize=10)
axs[i, 1].axis('off')
plt.suptitle('CHL: True vs Predicted (log scale) — 2020', fontsize=16)
plt.show()
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
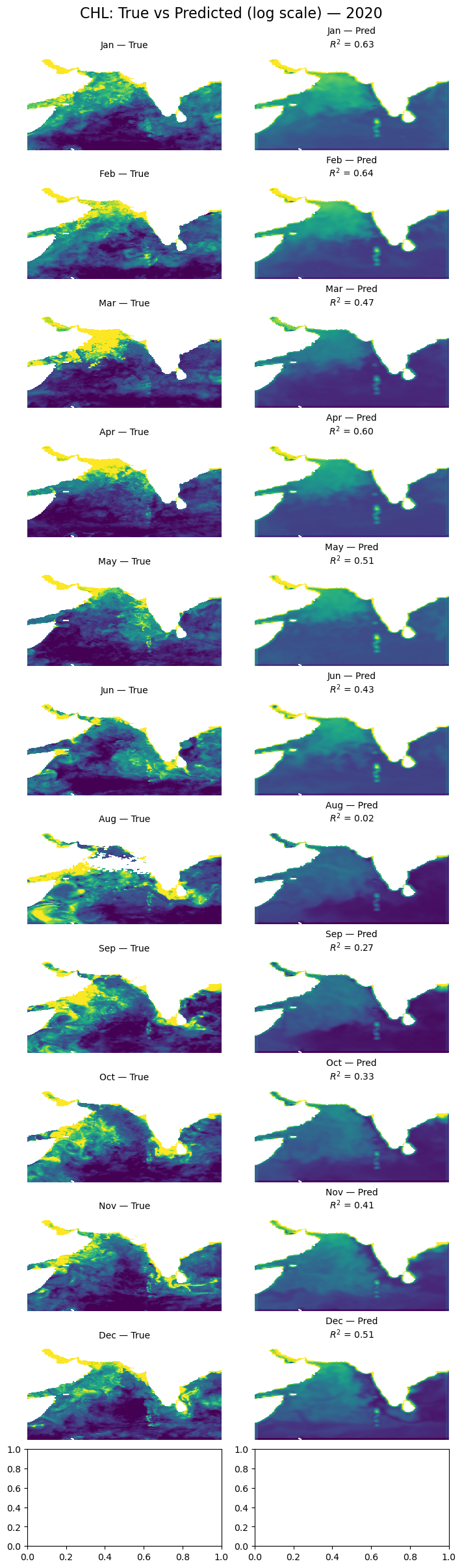
Glow around land#
It is a little hard to see but there is a “glow” on the land/ocean boundary. This is because we set land to 0 and the model is training on the land and using that land “0” to help make predictions at the land/ocean boundary.
Summary#
This is a simple CNNs model but it managed to do ok with just 2 variables. But we have to deal with the land mask. We will do that in Part 2. In Part 3, we will start doing a more realistic problem: gap-filling cloud-masked level 3 data. Then we will start getting more reasonable predictions and without all the ‘smudging’.